
1er site indépendant de comparaison d’assurance, lancé en septembre 2012
Un lieu unique pour comparer rapidement des centaines d’offres (assurances auto, moto, MRH, santé et emprunteur)
Volume : 2 500 000 devis/an

Apache Spark est un système de calcul distribué général haute performance.
Il propose des API haut niveau en Java, Scala, Python et R et contient un moteur d'optimisation générique.
Il contient plusieurs outils tels que Spark SQL pour la gestion de donnée en SQL, MLlib pour le machine learning, GraphX pour le processing de graph et Spark Streaming pour du micro-batching.

C'est très simple de démarrer : notebook Spark en Scala
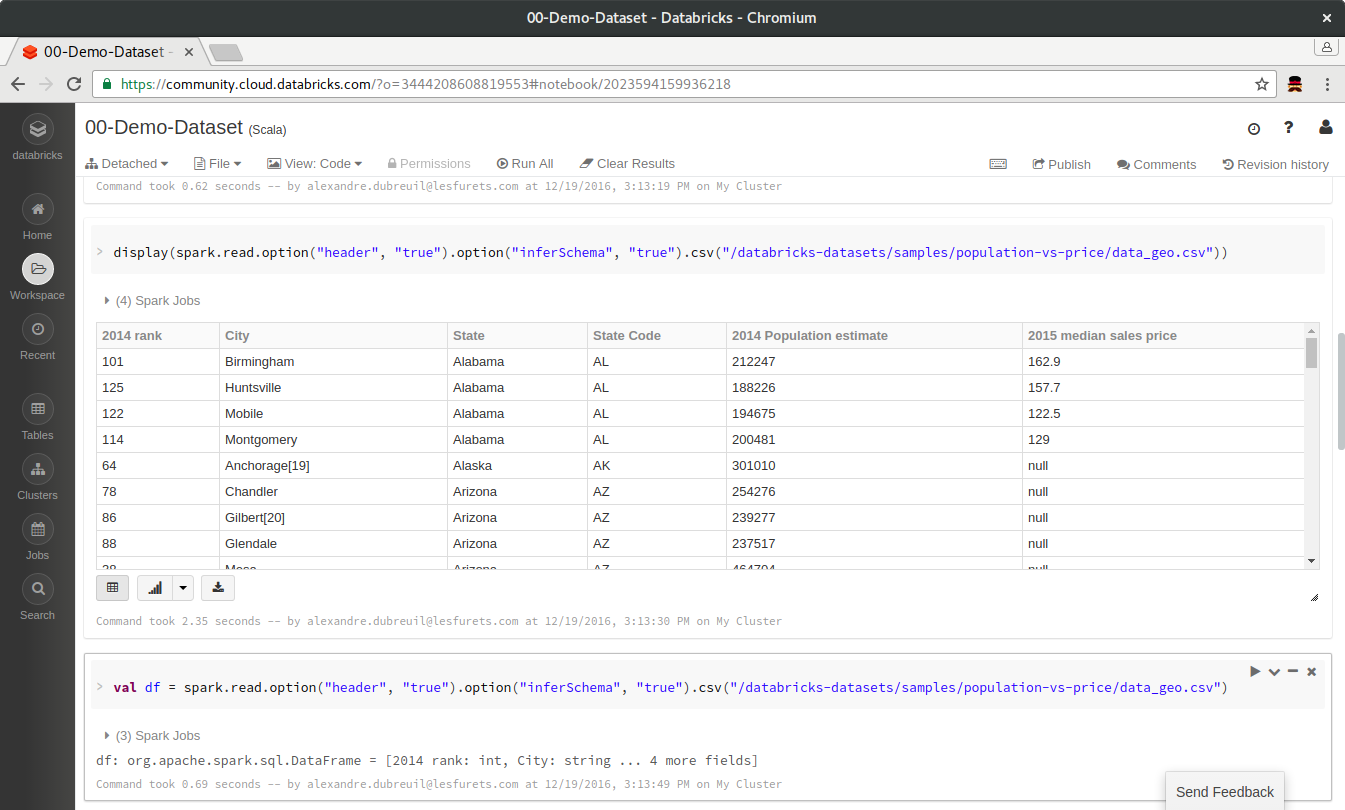
Le notebook permet
Bref, c'est la classe ...
... et en 2 minutes on trouve plusieurs cas d'usages :
... mais on se rend compte qu'on ne sait pas écrire du Scala

... mais surtout, on se rend compte qu'un notebook c'est pratique, mais ce n'est pas très industriel
Il suffit de l'ajouter en dépendance dans Maven
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.0.2</version>
</dependency>
Le 2.11 dans l'artifactId veut dire que Spark a été compilé avec Scala 2.11 (votre cluster Spark devra être démarré avec cette même version, afin d'éviter les problèmes de sérialisation entre les exécuteurs)
Il faut aussi ajouter l'API DataFrame
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.0.2</version>
</dependency>
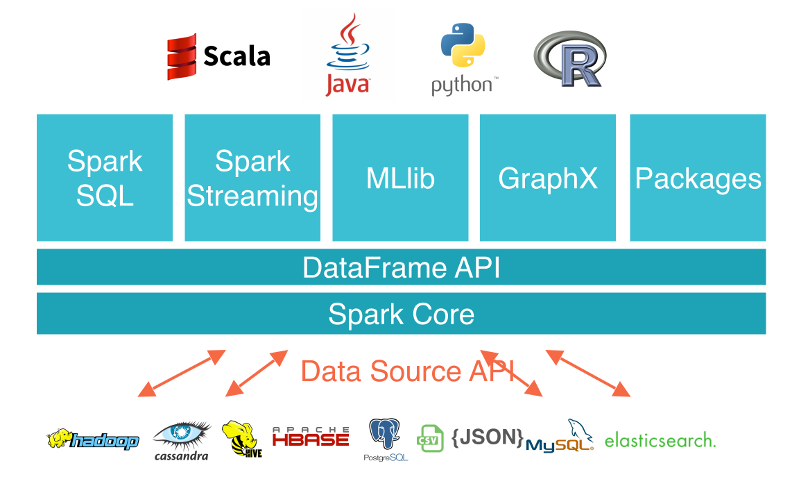
Plus ou moins chaque brique s'importe avec une dépendance
Le point d'entré est SparkSession
private static SparkSession spark = SparkSession.builder()
.appName("LesFurets.com - Spark")
.master("local[*]")
.getOrCreate();
public static void main(String[] args) {
spark.emptyDataFrame().show();
}
La machine qui instancie le SparkSession est ce qu'on appelle le driver, il contient le contexte et communique avec le cluster manager afin de lancer les exécutions sur les worker (ou exécuteur).
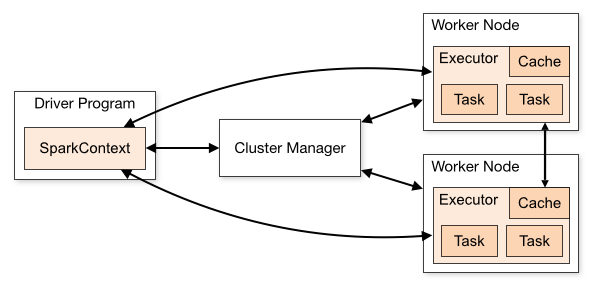
Apache Spark est un moteur en cluster, qui peut se démarrer en 2 modes : local ou standalone / cluster
Cela veut dire que le jar contenant votre programme est envoyé par le cluster manager (Standalone, Apache Mesos, Hadoop YARN) aux workers, et les datas sont sérialisés entre les JVM.
Corollaire : les workers n'ont pas directement accès aux variables du driver (ou des autres workers).
Et si on faisait un truc simple ?
Trouver la moyenne des prix, par formule, pour un assureur
DEMO TIME ! voir TarifsRun
spark.udf().register("readableFormule",
(UDF1<String, String>) String::toLowerCase, StringType);
Dataset<Row> averagePrime = tarifs
.filter((FilterFunction<Row>) value ->
value.<String>getAs("assureur")
.equals("Mon SUPER assureur"))
.groupBy("formule")
.agg(avg("prime").as("average"))
.withColumn("formuleReadable",
callUDF("readableFormule", col("formule")))
.orderBy(desc("average"));
averagePrime.show();
Qu'est-ce qui s'exécute sur les worker ? Et sur le driver ?
tarifs
.filter((FilterFunction<Row>) value ->
value.<String>getAs("assureur")
.equals("Mon SUPER assureur"))
.groupBy("formule")
.agg(avg("prime").as("average"))
.withColumn("formuleReadable",
callUDF("readableFormule", col("formule")))
.orderBy(desc("average"))
.show();
On appelle averagePrime.show() une opération terminale, tout le reste est lazy (pensez Java 8 Stream).
Entre chaque étape, Spark va potentiellement faire du shuffle (déplacement de données) entre les worker.
Pendant l'exécution, ces infos sont disponibles dans Spark UI. Pour voir ces informations après l'exécution, activer spark.eventLog.enabled et démarrer le Spark UI history server
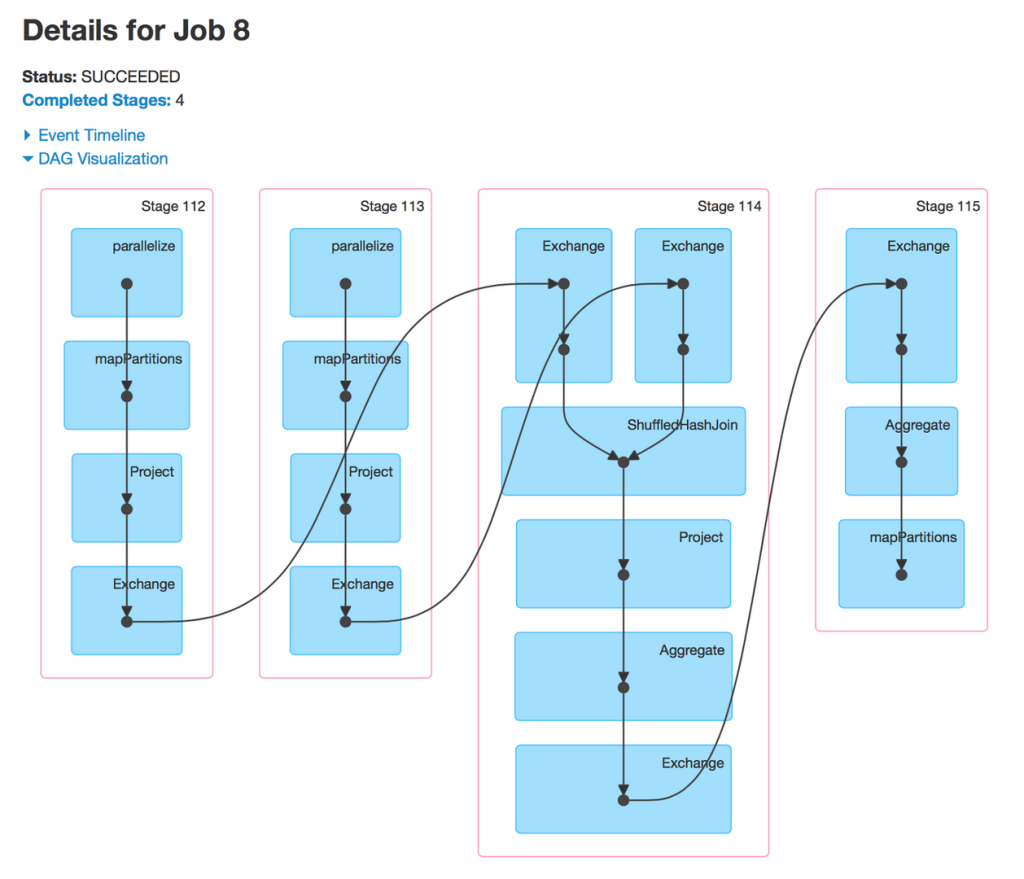
Quelle est cette classe Dataset (aussi appelé Dataframe) ?
Un DataFrame est une collection distribuée de data organisée en colonnes nommées et typées.
A partir de notre SparkSession on récupère un Dataset<Row> (soit un DataSet non-typé, appelé DataFrame).
// Lecture d'un fichier data.csv avec inférence de schéma
Dataset<Row> data = spark.read()
.option("inferSchema", true)
.csv("data.csv");
Les DataFrame ont un schéma, même si ils sont typés Row comme Dataset<Row>
data.printSchema();
root
|-- uid: string (nullable = true)
|-- email_hash: integer (nullable = true)
|-- date: timestamp (nullable = true)
|-- heure: string (nullable = true)
|-- module: string (nullable = true)
Si vous utilisez SparkSQL, vous utilisez les DataFrame, et dans les 2 cas les plans d'exécution seront optimisés par Catalyst
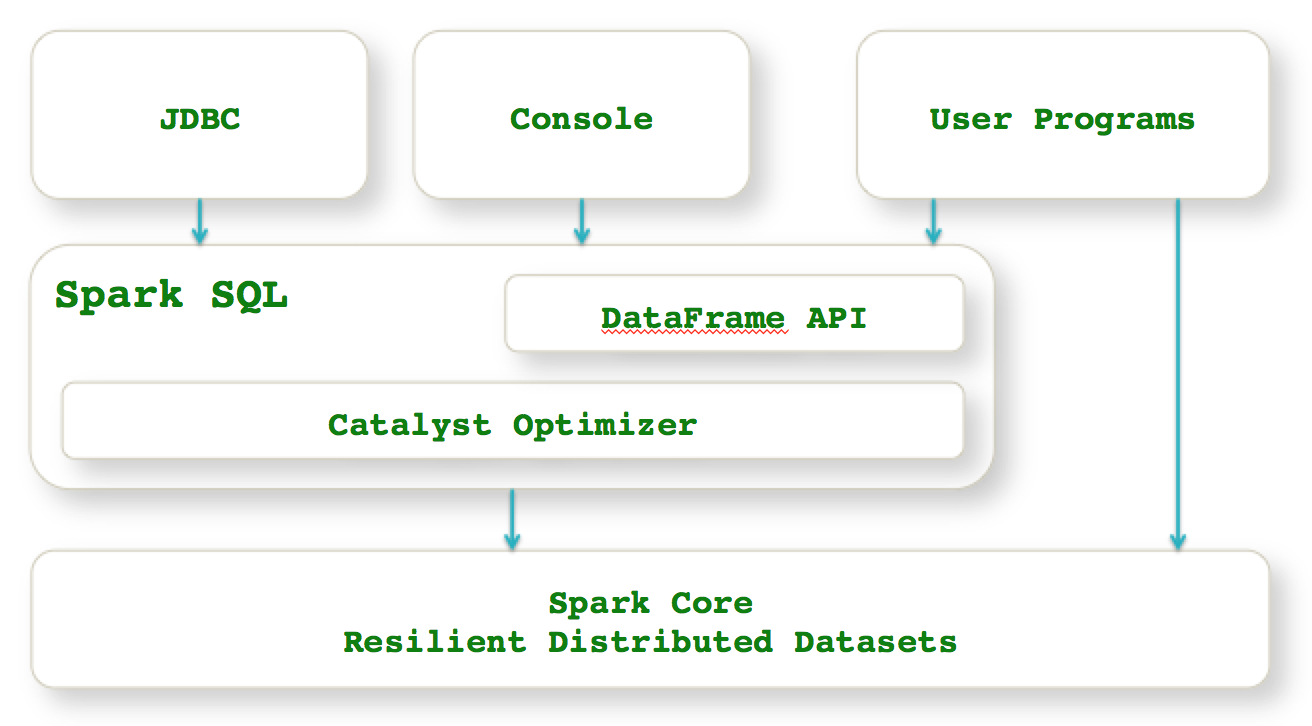
On récupère un DataSet tel quel, ou à partir d'un DataFrame typé.
Soit Question un Java Bean qui correspond à une question du formulaire LesFurets
// Convertion du Dataset<Row> en Dataset<Question>
Dataset<Question> domainData = data
.as(Encoders.bean(Question.class))
Le DataSet, en plus d'avoir un schéma, est typé, par exemple avec Question comme Dataset<Question>
À partir de Spark 2.0, SparkSQL, DataFrames and DataSets représentent le même composant
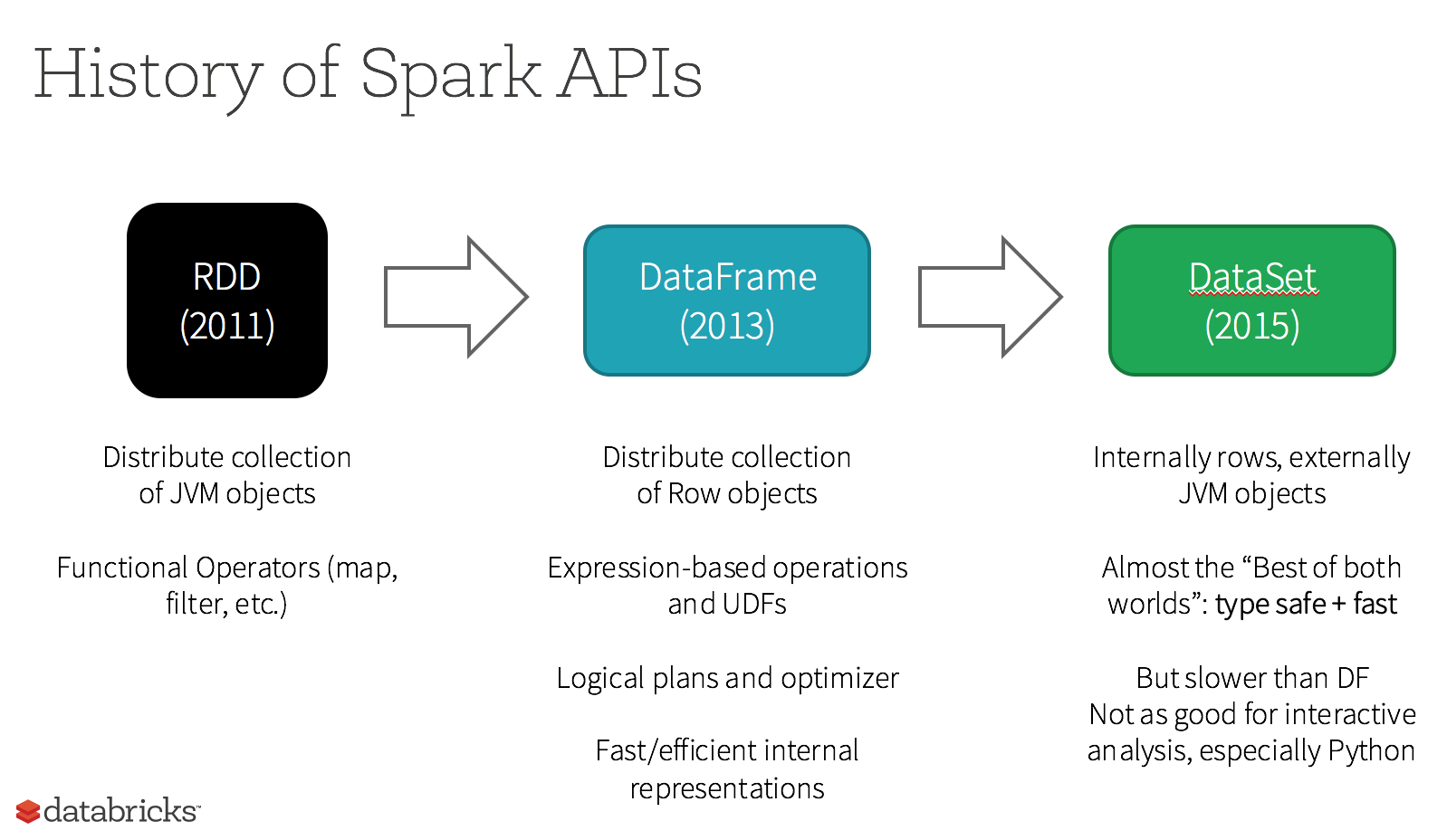
Les Resilient Distributed Datasets (RDDs) sont la plomberie interne de spark : pas besoin d'y toucher sauf pour intéragir avec des composants legacy ou utiliser certaines fonctionnalités avancées (RDD#partitionBy)
// Récupération du RDD sous-jacent au dataset
RDD<Question> rdd = domainData.rdd();
// API Java du RDD
JavaRDD<Question> javaRDD = domainData.javaRDD();
L'interface entre les les DataFrame et les RDDs est simple
Dataset<Row> dataFrame = spark.createDataFrame(rdd, structType);
Catalyst optimise le plan d'exécution de votre programme, disponible avec : Dataset#explain
Le code généré par Spark est optimisé pour s'exécuter rapidement, c'est le résultat du projet Tungsten (whole-stage codegen)
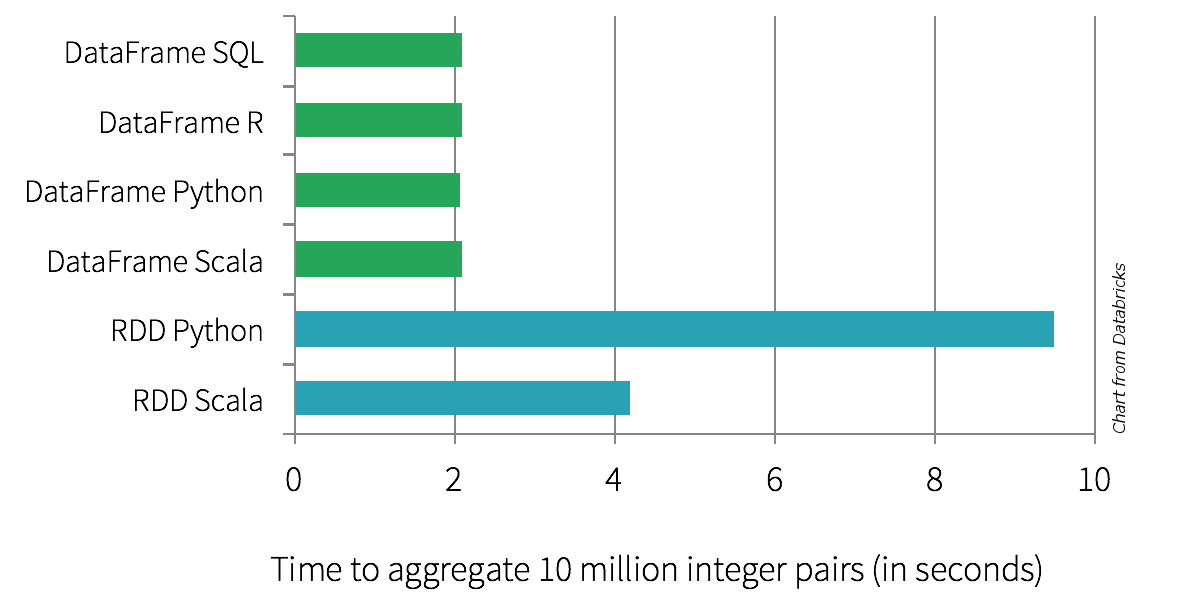
Et si on testait notre code ?
DEMO TIME ! voir TarifsRunTest
@BeforeEach
public void before() {
List rows = Arrays.asList(
RowFactory.create("F1", 50d, "assureur"),
RowFactory.create("F1", 100d, "assureur"),
RowFactory.create("F1", 70d, "assureur"));
StructField formule = new StructField("formule" ...);
StructField prime = new StructField("prime" ...);
StructField assureur = new StructField("assureur", ...);
StructType structType = new StructType(
new StructField[]{formule, prime, assureur});
tarifs = spark.createDataFrame(rows, structType);
}
@Test
public void should_calculate_average_by_formule_ordered() {
Dataset averagePrime = TarifsRun.averagePrime(tarifs);
assertEquals(2,
averagePrime.count());
assertEquals(1,
averagePrime.first().getAs("formule"));
assertEquals("formule 1",
averagePrime.first().getAs("formuleReadable"));
assertEquals(75,
(double) averagePrime.first().getAs("average"));
}
Idéalement :
Mais sommes-nous limité en java ?
... oui, un peu
- On aimerait un notebook avec REPL (on peut quand même écrire du Scala pour prototyper, c'est la même API)
- Il faut bien connaître l'API (mal) documentée pour Java
- Il est facile de tomber dans des implémentations trop verbeuses
- On est souvent obligé de passer des sérialiseurs de type (par exemple Encoders.STRING())
Par exemple dans ma première implémentation d'un word count...
Dataset<Row> wordCount = lines
.flatMap((FlatMapFunction<Row, String>) row -> {
String[] words = row.<String>getAs("line").split(" ");
return asList(words).iterator();
}, STRING())
.map((MapFunction<String, Tuple2<String, Integer>>) word ->
new Tuple2<>(word, 1), tuple(STRING(), INT()))
.toDF("word", "count")
.groupBy("word")
.sum("count")
.orderBy(desc("sum(count)"))
... on remarque l'usage de flapMap et map, qui prennent des lambdas (très générique mais un peu verbeux)
... mais ce même word count peut s'écrire de manière beaucoup moins verbeuse en connaissant bien l'API
Dataset<Row> wordCount = lines
.select(split(col("lines"), " ").alias("words"))
.select(explode(col("words")).alias("word"))
.groupBy("word")
.count()
.orderBy(desc("count"));
... même si c'est un peu magique

Best tip of the month :
La plupart des fonctions pour select, map, flapMap, reduce, filter, etc., dont vous aurez besoin sont dans org.apache.spark.sql.functions (comme dans la slide précédante)
Avant d'écrire une lambda à la main, cherchez dans ce package (non-documenté)
Malheureusement, l'usage des lambdas de Java 8 est décevant, on est obligé de les caster.
Par exemple, pour récupérer le dernier élément d'un groupe :
Dataset<Tuple2<String, TarificationJoin>> tupleTarif =
tarification
.groupByKey((MapFunction<TarificationJoin, String>)
TarificationJoin::getOffreUid, STRING())
.reduceGroups((ReduceFunction<TarificationJoin>) (v1, v2) ->
v1.getSnapshotId()
.compareTo(v2.getSnapshotId()) > 0 ? v1 : v2);
Pourtant, ces méthodes acceptent bien des Single Abstract Method interfaces (SAM Interfaces), mais impossible de les appeler directement parce qu'elles sont "overload" pour les appels en Scala. L'exemple précédent devrait être :
Dataset<Tuple2<String, TarificationJoin>> tupleTarif =
tarification
.groupByKey(TarificationJoin::getOffreUid, STRING())
.reduceGroups((v1, v2) -> v1.getSnapshotId()
.compareTo(v2.getSnapshotId()) > 0 ? v1 : v2);
Le problème est connu et vient de la compatibilité bytecode entre Scala et Java, qui est réglé par Scala 2.12. Le support Spark de cette version de Scala n'est pas triviale, voir les discussions sur le JIRA de Spark : SPARK-14220 et SPARK-14643.
En Java : il faut aussi passer explicitement les sérialiseurs org.apache.spark.sql.Encoders.*
Dataset<Tuple2<String, TarificationJoin>> tupleTarif =
tarification
.groupByKey((MapFunction<TarificationJoin, String>)
TarificationJoin::getOffreUid, STRING())
.reduceGroups((ReduceFunction<TarificationJoin>) (v1, v2) ->
v1.getSnapshotId()
.compareTo(v2.getSnapshotId()) > 0 ? v1 : v2);
Ce dont on n'a pas parlé
Face à la compétition (Apache Storm, Apache Flink, Hadoop MapReduce, etc.), Apache Spark se démarque par une facilité d'utilisation, une excellente performance, et une API léchée (et testable !).
Mais surtout, Apache Spark s'intègre-t-il avec notre tooling Java ?
Oui, grâce à une API utilisable avec Java 8 et testable, aux UDF, et au lancement facile dans l'IDE

- Ces slides et ce code (avec des exemples d'annotations Spark JUnit4 et JUnit5)
https://github.com/lesfurets/lesfurets-conference
- Articles Spark en Java et Spark unit testing
https://beastie.lesfurets.com/articles